
In one of the previous chapters, we discussed RAG (Retrieval-Augmented Generation), where AI looks up information before answering.
A natural follow-up question is: how does it actually find the right information from thousands of pages?
It is not scanning documents the way a person reads a book. The system uses two ideas together: embeddings and vector databases.
This post explains both in plain, practical language.
In one sentence: embeddings help AI understand similarity, and vector databases help AI retrieve it fast.
The core problem: finding the right information fast
Imagine you have:
- 1,000 pages of notes
- 100 PDFs
- 10 textbooks
Now someone asks: "How do plants make food?"
You would not read everything from page one. You would jump to the most relevant section.
AI faces the same challenge, just at a much larger scale.
What are embeddings?
Embeddings are a way to convert text into numbers that represent meaning.
Key idea: these numbers represent semantic meaning, not just word spelling.
Computers cannot work with "meaning" directly the way humans do. So a sentence is transformed into a numerical representation. If two sentences mean similar things, their embeddings are close to each other.
For example:
- "I love cricket"
- "I enjoy playing cricket"
Different words, similar intent. Their embeddings are usually close.
Simple analogy
Think of a city map where similar places are often close to each other, like schools near other schools or hospitals near medical stores:
- Similar ideas are close together
- Unrelated ideas are far apart
So "cricket" and "football" may sit near each other, while "cricket" and "cooking" are usually far apart.
Embeddings create this kind of meaning map.
This is why AI can connect related sentences even when wording is different.
Why embeddings matter
They allow search by meaning, not just exact words.
Suppose a user asks: "How to treat fever?"
A document says: "Ways to reduce body temperature."
A strict keyword search might miss this match because the wording is different.
Embedding-based search can still connect the two because the meaning overlaps.
That is the big shift: semantic match over word match.
Why this matters: better retrieval means better final answers in RAG pipelines.
What is a vector database?
Once text is converted into embeddings, those vectors need to be stored somewhere and searched efficiently.
A vector database is built for exactly this purpose:
- Store embeddings
- Find the closest matches quickly
So instead of searching for exact words, it searches for nearest meaning.
Simple analogy
Think of a library:
- Old system: books arranged alphabetically
- Vector database: books grouped by topic similarity
Books about plants are close to other plant-related books. Sports content is grouped near sports.
This makes retrieval faster and more relevant.
Think of it this way: keyword search asks "Do these words match?" while vector search asks "Do these meanings match?"
How it works together (step by step)
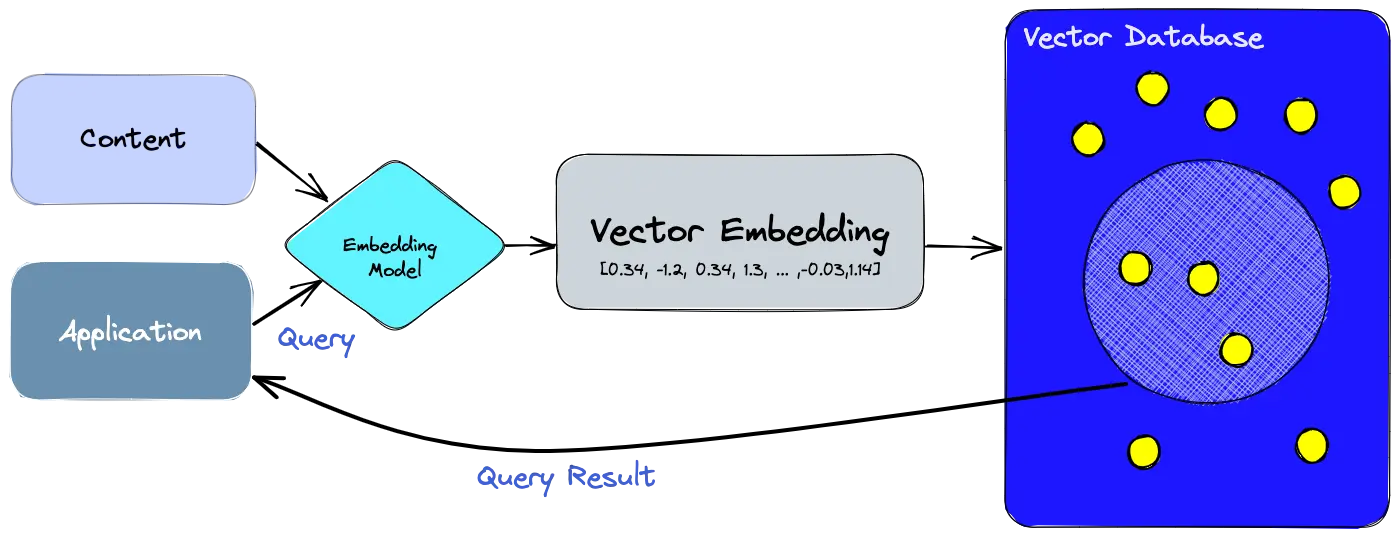
This is the full flow in simple terms:
- Store knowledge
Documents are split into smaller sections (chunks).
Each chunk is converted into an embedding and stored in the vector database.
- User asks a question
Example: "Explain photosynthesis."
- Convert question into embedding
The question is also transformed into numbers.
- Find similar chunks
The vector database finds the closest chunk embeddings by meaning.
- Send context to the model
Those relevant chunks are passed to the LLM.
- Generate final answer
The model writes a clear response using the retrieved context.
In one line:
Question -> meaning vector -> similar chunks -> LLM -> answer.
You can also read it as:
Question -> Embedding -> Retrieval -> Generation
How this connects to RAG
RAG is basically this pipeline in action.
- Retrieval = vector database search
- Generation = LLM response
So embeddings plus vector databases act like the "library system" inside RAG.
Shortcut memory line: RAG retrieval works because embeddings make meaning searchable.
Real-life example
Imagine a school chatbot where all textbooks are indexed in a vector database.
A student asks: "Why do plants need sunlight?"
The system retrieves the relevant textbook section, then the model explains it in simple language.
The student gets a focused answer without manually searching through chapters.
Keyword search vs meaning search
- Keyword search looks for exact terms.
- Meaning search looks for intent and semantic similarity.
Example:
- Query: "heart attack causes"
- Document text: "reasons for cardiac arrest"
Keyword match may fail. Meaning-based retrieval can still find the right section.
What is chunking, and why it matters
Large documents are usually split into smaller pieces called chunks.
This helps because:
- Search becomes more accurate
- Relevant context is easier to isolate
- Retrieval is faster and cleaner
Instead of handing the model an entire book, the system gives only the most relevant sections.
Practical benefit: smaller, relevant context usually improves both speed and answer quality.
Can this still go wrong?
Yes. Retrieval systems are powerful, but not perfect.
Common failure cases:
- Wrong chunks are retrieved
- Important source data is missing
- Chunking is poor, so context gets split badly
When retrieval quality drops, answer quality drops too. It is like opening the wrong page of a textbook and confidently summarizing it.
Good generation cannot fully compensate for poor retrieval.
One-line takeaway
Embeddings turn meaning into numbers, and vector databases make that meaning searchable at speed.
Big-picture connection
At this point, the full stack should feel clear:
- LLMs generate answers
- Prompting shapes answers
- RAG brings in external knowledge
- Embeddings and vector databases help retrieve that knowledge
Together, they make modern AI assistants far more useful than plain text generation alone.
Final mental model:
LLM = writerVector DB = librarianEmbeddings = meaning index